Navmaharashtra Shikshan Mandal Aabasaheb Kakade College Of B Pharmacy,Bodhegao
The patient's primary care electronic medical record is used to create a comprehensive digital document, forming the foundation of the IPGx care model. This document includes specific information about the patient's medical history. The clinic collects additional information from the patient, conducts a physical examination, and takes samples for analysis at a specialized laboratory. Simultaneously, data analysis is carried out based on the collected information and laboratory results. A report is sent to the referring physician, highlighting medication-related issues and suggesting alternatives. Patients can also participate in a research registry to assess their quality of life. The IPGx model employs artificial intelligence, particularly the Clinical Semantic Network (CSN), to analyze symptoms in the patient's medical records related to medication problems. In the bioanalytic phase, genetic factors affecting medication response are investigated, following clinical guidelines. Single Nucleotide Polymorphisms (SNPs) are identified and combined with health data to predict disease outcomes, aiding physicians in clinical management. The Molecular Dx pharmacogenomic (PGx) assay assesses a wide range of medications and therapeutic symptoms efficiently. Candidate symptoms and genetic variations are validated by measuring medication blood levels. This provides a more personalized understanding of drug-gene interactions. The Clinical Semantic Network (CSN) plays a crucial role in identifying medications and potential interactions. It considers various factors, leading to a polypharmacy report that helps clinicians understand drug interactions. This process generates a medication management summary report, highlighting high-probability drug-gene and drug-drug interactions, providing a better understanding of how medications affect the patient.
Pharmacogenomics: Pharmacogenomics is the study of the role of the genome in drug response. Its name (pharmaco- + genomics) reflects its combining of pharmacology and genomics. Pharmacogenomics analyzes how the genetic makeup of a patient affects their response to drugs.[1] It deals with the influence of acquired and inherited genetic variation on drug response, by correlating DNA mutations (including single-nucleotide polymorphisms, copy number variations, and insertions/deletions) with pharmacokinetic (drug absorption, distribution, metabolism, and elimination), pharmacodynamic (effects mediated through a drug's biological targets), and/or immunogenic endpoints.[2][3][4] Pharmacogenomics aims to develop rational means to optimize drug therapy, with regard to the patients' genotype, to achieve maximum efficiency with minimal adverse effects.[5] It is hoped that by using pharmacogenomics, pharmaceutical drug treatments can deviate from what is dubbed as the "one-dose-fits-all" approach. Pharmacogenomics also attempts to eliminate trial-and-error in prescribing, allowing physicians to take into consideration their patient's genes, the functionality of these genes, and how this may affect the efficacy of the patient's current or future treatments (and where applicable, provide an explanation for the failure of past treatments).[6][7] Such approaches promise the advent of precision medicine and even personalized medicine, in which drugs and drug combinations are optimized for narrow subsets of patients or even for each individual's unique genetic makeup. Whether used to explain a patient's response (or lack of it) to a treatment, or to act as a predictive tool, it hopes to achieve better treatment outcomes and greater efficacy, and reduce drug toxicities and adverse drug reactions (ADRs). For patients who do not respond to a treatment, alternative therapies can be prescribed that would best suit their requirements. In order to provide pharmacogenomic recommendations for a given drug, two possible types of input can be used: genotyping, or exome or whole genome sequencing.[8] Sequencing provides many more data points, including detection of mutations that prematurely terminate the synthesized protein (early stop codon)
DEVELOPMENT:
Pharmacogenomics was first recognized by Pythagoras around 510 BC when he made a connection between the dangers of fava bean ingestion with hemolytic anemia and oxidative stress. In the 1950s, this identification was validated and attributed to deficiency of G6PD, and called favism.[10][11] Although the first official publication was not until 1961,[12] the unofficial beginnings of this science were around the 1950s. Reports of prolonged paralysis and fatal reactions linked to genetic variants in patients who lacked butyrylcholinesterase ('pseudocholinesterase') following succinylcholine injection during anesthesia were first reported in 1956.[2][13] The term pharmacogenetic was first coined in 1959 by Friedrich Vogel of Heidelberg, Germany (although some papers suggest it was 1957 or 1958).[13] In the late 1960s, twin studies supported the inference of genetic involvement in drug metabolism, with identical twins sharing remarkable similarities in drug response compared to fraternal twins.[14] The term pharmacogenomics first began appearing around the 1990s.[11]
The first FDA approval of a pharmacogenetic test was in 2005[9] (for alleles in CYP2D6 and CYP2C19).
Literature Survey:-
1)Patrick Silva et.al :
Managing chronic diseases often involves multiple medications, leading to challenges like polypharmacy and suboptimal healthcare utilization. Despite documented issues and rising costs, effective tools to address these challenges are scarce. This report highlights the potential of proactive medication management and pharmacogenomic testing in improving health outcomes and reducing costs. The described methodologies integrate symptom signals, chief complaints, and pharmacogenomic analysis to monitor drug–gene pairs and interactions. Validation in a virtual patient case demonstrated the detection of clinically significant interactions. This effort aims to establish a regional database for tracking outcomes in a bioanalytically-informed medication management program, offering clinical decision support in primary care.
2) Roseann S. Gammal, Pharm.D et.al:-
Clinicians recognize patients' varied responses to the same medication dose, influenced by genetic factors. Genetic variations in pharmacogenes, governing drug-metabolizing enzymes, impact protein structure, affecting drug pharmacokinetics/pharmacodynamics. Human leukocyte antigen (HLA) gene variants influence susceptibility to severe immune reactions. Genetics guides personalized medication choices, yet should be considered with other clinical variables. While genetics predicts responses, it's not deterministic; factors like drug-drug interactions require consideration. Examples in germline pharmacogenomics involve cytochrome P450 (CYP) enzymes, determining a spectrum from ultrarapid to poor metabolizers. Outcomes depend on factors like therapeutic index and influence of metabolic pathways, crucial for precise clinical interpretation.
3)Konrad J. Karczewski, et.al :-
Pharmacogenomics profoundly influences pharmaceutical drug development, shaping it from early discovery to clinical trials. Cheminformatics and pathway analysis identify gene targets, guiding selection of small molecules as drug candidates. Uncovering pharmacogenomic variants is crucial for designing safe clinical trials, enhancing drug progression. This integration boosts efficiency and success rates, reducing costs and improving safety. Through association and expression methods, pharmacogenomics identifies disease-specific gene targets, refined by cheminformatics for testing. In later trials, it guides the design of Phase III trials, excluding non-responders and customizing drug interventions for positive responses. This holistic approach underscores pharmacogenomics' pivotal role in optimizing drug discovery.
4) Richard D. Boyce, PhD et.al:
The development of a semantic model for pharmacogenetic content in Structured Product Labels (SPLs) utilized real use cases and representative pharmacogenomics statements. Focusing on SPLs, relevant sentences were analyzed to identify entities and relationships using the Cmap concept mapping tool. This agile, informal modeling approach allows rapid development with the intention to transition to a more formal model through iterative refinement. Incorporating perspectives from pharmacological and translational considerations, this iterative process aims to enhance accuracy and comprehensiveness over time, providing a robust framework for representing pharmacogenomic information within SPLs.
5) CAROLINE B. AHLERS et.al :-
Semantic groups play a vital role in organizing UMLS semantic types, enhancing clarity and coherence in handling pharmacogenomics information. In Enhanced SemRep, five groups—Substance, Anatomy, Living Being, Process, and Pathology—provide a structured framework for ontological semantic predications. The 'Substance' group includes diverse entities, facilitating comprehensive information handling in pharmacogenomics. 'Anatomy' categorizes anatomical structures, 'Living Being' covers various organisms, 'Process' involves physiological aspects, and 'Pathology' deals with abnormalities and diseases. The integration of these components establishes a robust system for personalized pharmacotherapy decision support. Historical challenges in clinical decision support systems, including knowledge deficiency and data limitations, are addressed through this integrated approach, fostering successful adoption and impact in personalized pharmacotherapy.
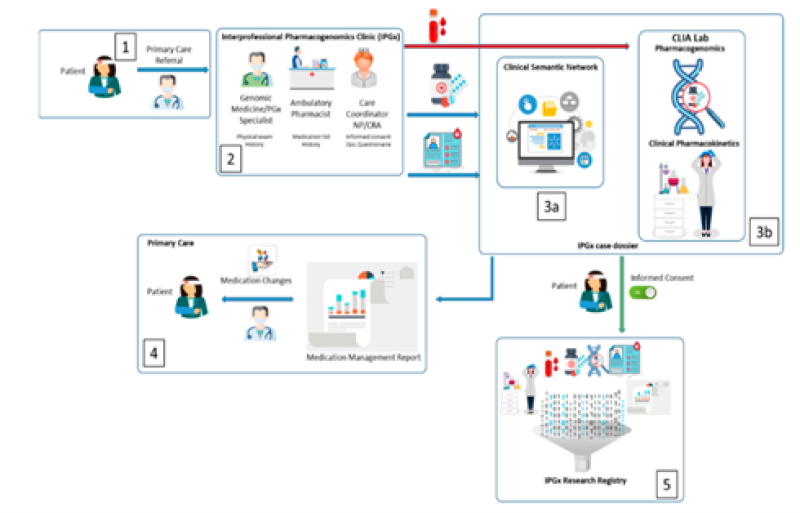
1. Clinical environment and process
b). Simultaneously, they process the patient's samples in the lab for further analysis.
2. Medical Record Analysis and the Clinical Sematic Network
In the IPGx model, artificial intelligence is used to analyse symptoms found in electronic medical records that might suggest problems with a patient's medication. They use a tool called the Clinical Semantic Network (CSN) from Goldblatt Systems, Inc., based in Tucson, Arizona. This system can process symptoms and complaints from the Texas A&M Primary Care medical record, following the HL7 clinical document architecture (CDA). The IPGx CoC data in the CDA includes information like chief complaints (related to drug side effects and symptoms), known diagnoses, and prescribed medications. This data is transferred from the electronic health record into the CSN, making it easy for the CSN to understand and work with this specific patient's data. The CSN is built using professional-grade software, including Oracle, DOM, Hibernate, and Java. It takes data stored in a structured way and turns it into a format that artificial intelligence can work with, enabling predictive analytics and making it computationally manageable. This system helps identify potential medication issues by analysing the patient's symptoms and medical history.
3. Bioanalytic phase
In the bioanalytic phase of the IPGx model, they delve into specific and actionable genetic targets related to how medications work (according to Clinical Pharmacogenetics Implementation Consortium or CPIC guidelines). The aim is to confirm how a person's genetic makeup influences the levels of medication in their bloodstream when they're taking it regularly. This analysis provides insights into how genetics affect the response to medications, which is crucial for personalized treatment.
4. Clinical Pharmacogenomics
Genetic variations known as SNPs (Single Nucleotide Polymorphisms) are identified through both genomic and pharmacogenomic analyses. These SNPs, when combined with personal health and psychosocial data, can be used to create a model for predicting disease outcomes. Additionally, this information can serve as a valuable tool to aid physicians in clinical management. The Molecular Dx pharmacogenomic (PGx) assay is designed to assess a wide range of medications andherapeutic symptoms. To ensure efficiency and a fast turnaround time, the MolecularDx Comprehensive PGx panel is used, particularly suitable for situations with low daily testing volumes.
Table
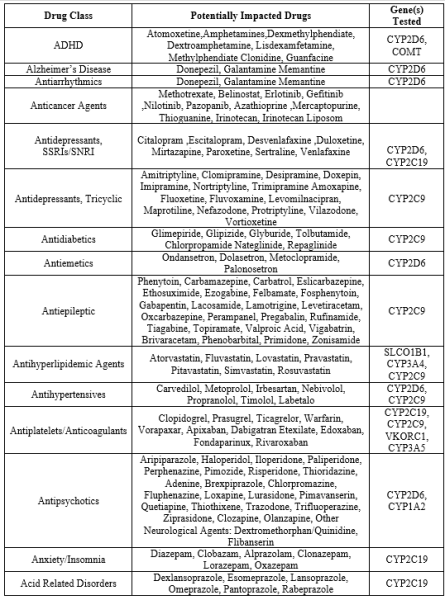
Candidate pharmacologic symptoms coupled with genotypes that portend drug–drug and drug–gene interactions can be further validated by the measurement of steady state blood concentrations of the medications of interest. Under the IPGx protocol, target drugs corresponding to the drug–gene pairs in Table 2 and their metabolites are measured utilizing a validated liquid chromatography mass spectrometry assay. Such results were not entered into the virtual exercise presented in this report, but are available for use in clinical practice.
Candidate symptoms that might be linked to drug interactions, along with the genetic variations associated with drug-to-drug and drug-to-gene interactions, can be substantiated by measuring the steady state blood levels of the relevant medications. In the IPGx protocol, they measure specific drugs that correspond to the drug-gene pairs listed in Table 2, as well as the compounds they break down into (metabolites). To do this, they use a validated method known as liquid chromatography mass spectrometry. While these results aren't included in the virtual exercise described in the report, they are accessible for use in actual clinical practice. This approach ensures a more comprehensive understanding of how genetic factors and medications interact in individual patients, contributing to more personalized and effective medical care.
The Clinical Semantic Network (CSN) plays a crucial role in breaking down and improving the process of identifying medications. It takes into account various factors such as the medication's molecular weight, how it's eliminated from the body, its classification according to the Anatomical Therapeutic Chemical (ATC) system, how it's distributed in the body, bioavailability, how long it stays in the body, its anticholinergic effects, steady state levels, and its interactions with enzymes like CYP450 or transporters. With this information, the CSN has enabled the creation of a polypharmacy report. This report can be used by clinicians in real time to get a comprehensive yet clear picture of a patient's symptoms, complaints, diagnoses, and the medications they are taking. It helps identify potential drug interactions (both gene-related and between different drugs) that might be the root cause of certain symptoms. The result of this function is a medication management summary report, which highlights high-probability and actionable drug-gene and drug-drug interactions based on guidelines from the Clinical Pharmacogenetics Implementation Consortium (CPIC). These interactions can ideally be confirmed through genetic testing and clinical pharmacokinetic assays, providing a more accurate understanding of how medications might be affecting the patient[15]
Clinical Sematic Report:
The Semantic Network consists of semantic types and semantic relationships. Semantic types are broad subject categories, like Disease or Syndrome or Clinical Drug. Semantic relationships are useful relationships that exist between semantic types. For example: Clinical Drug treats Disease or Syndrome. The Semantic Network is used in applications to help interpret meaning.
Some semantic types:
The Semantic Network consists of:
Semantic types (high level categories)
Semantic relationships (relationships between semantic types)
The Semantic Network can be used to categorize any medical vocabulary There are 133 semantic types in the Semantic Network. Every Metathesaurus concept is assigned at least one semantic type; very few terms are assigned as many as five semantic types. Semantic types are listed in the Metathesaurus file MRSTY.RRF. Semantic types and semantic relationships create a network that represents the biomedical domain. Semantic types and relationships help with interpreting the meaning that has been assigned to the Metathesaurus concept.
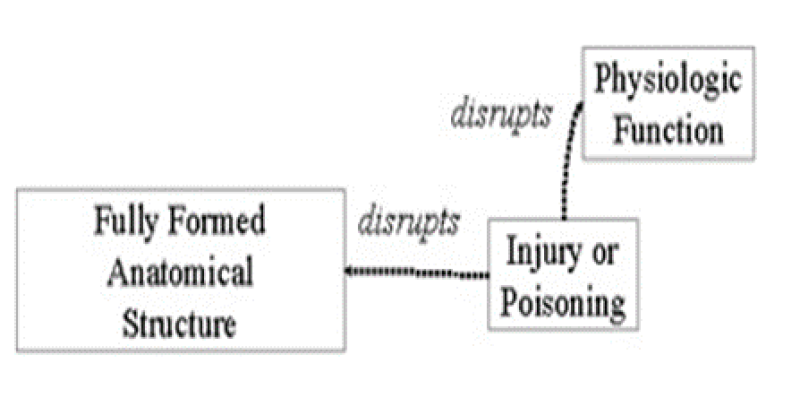
The graphic above illustrates two semantic relationships

Identifiers in clinical sematic network:
The information associated with each semantic type includes:
The information associated with each relationship includes:
Sematic types
Examples of the semantic types:
Semantic types are arranged in a hierarchy which is organized into two main categories, Entity and Event.
Examples of Entity semantic types are:
Examples of Event semantic types are:
Semantic types exist in differing levels of granularity or specificity. In the Metathesaurus, semantic type is assigned at the most specific level available. For example, the concept trout would receive the semantic type 'fish', not the semantic type 'animal' because fish is more specific.
Sematic Relationships
Of the fifty-four semantic relationships the primary link between most semantic types is the isa relationship. The 'isa' relationship establishes the hierarchy of types within the Semantic Network and is used for deciding on the most specific semantic type available for assignment to a Metathesaurus concept.
Some examples of the 'isa' relationship:
There are five major, non-hierarchical relationships:
Sematic Relationship at the Concept Level
Semantic relationships may or may not hold at the concept level.
For example, the relationship Clinical Drug causes Disease or Syndrome does not hold at the concept level for Aspirin and Cancer. Aspirin does not cause cancer. Not all relationships that apply at the concept level are indicated in the Semantic Network. Specifically: The above relationship does not hold between the concepts fever and body weight. Fever is not an evaluation of body weight. Click on the image below to expand the graphical representation of a portion of the UMLS Semantic Network. The above relationship does not hold between the concepts fever and body weight. Fever is not an evaluation of body weight. Click on the image below to expand the graphical representation of a portion of the UMLS Semantic Network.
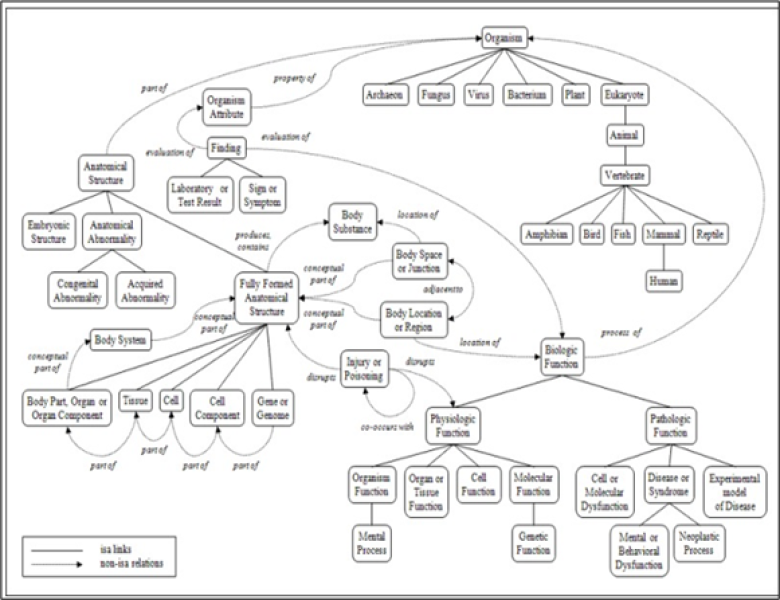
Parent-child(border/narrower)relationship
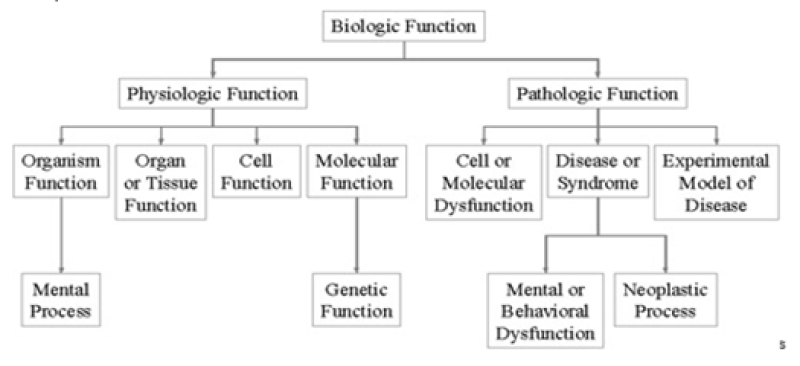
One of the more important relationships within the Semantic Network is the Parent-Child, or Broader-Narrower, relationship. This relationship illustrates the hierarchies that exist between biomedical concepts. Child (narrower) relationships can be thought of as a subtype. For example, the semantic type Biologic Function is the parent of, or broader than, the semantic type Physiologic Function. It is important to note that the level of granularity varies across the Network. For example, a child of Physical Object is Manufactured Object. Manufactured Object has only two child terms, Medical Device and Research Device. It is clear that there are manufactured objects other than medical devices and research devices. Rather than expand the number of semantic types, concepts that are neither medical devices nor research devices are simply assigned the broader semantic type
Manufactured Object.
Principle of pharmacogenomics :
Clinicians acknowledge that patients can react differently to the same medication dose, and this variability is influenced by genetic factors. Genetic variations in pharmacogenes, responsible for drug-metabolizing enzymes, transporters, targets, and receptors, contribute to differences in protein structure and function, impacting a drug's pharmacokinetics and/or pharmacodynamics. Human leukocyte antigen (HLA) gene variations can influence susceptibility to severe immune-related reactions to medications. Genetics serves as a clinical tool for personalized medication choices and dosages, although it should be considered alongside other clinical variables. While genetics can predict responses, it is not deterministic, and other factors like drug-drug interactions must be considered for accurate interpretation of pharmacogenomic test results. For instance, a patient genetically classified as a CYP2D6 normal metabolizer may exhibit poor metabolism when taking a strong CYP2D6 inhibitor. Many clinically relevant examples of germline pharmacogenomics involve genes that encode drug-metabolizing enzymes, such as cytochrome P450 (CYP) enzymes. Genetic variations can result in a range of enzyme activity, from ultrarapid metabolizer to poor metabolizer, based on the specific gene. If an active drug is metabolized by the enzyme into an inactive form, increased enzyme activity can lead to treatment failure, while decreased enzyme activity can cause toxicity. Conversely, if the drug is a prodrug that needs to be metabolized into its active form, the opposite is true. Whether these outcomes are observed in clinical practice depends on various factors, including the drug's therapeutic index and the influence of other metabolic pathways on drug disposition and response.[16]
Methods for discovery :
Pharmacogenomics plays a pivotal role in shaping the drug development process within the pharmaceutical industry, starting from the early stages of drug discovery (see Figure 4). Cheminformatics and pathway analysis contribute to identifying appropriate gene targets, paving the way for the selection of small molecules as initial candidates for potential drugs. Moreover, uncovering pharmacogenomic variants is crucial for designing clinical trials, ensuring a safer and more effective progression of drugs through the pharmaceutical pipeline. This integration of pharmacogenomic insights enhances the efficiency and success rates of drug development within the industry. Pharmacogenomics proves valuable across various stages of the drug discovery pipeline, offering cost reduction, increased efficiency, and enhanced safety measures. Initially, association, expression methods, and pathway analysis help pinpoint potential gene targets for specific diseases. Cheminformatics then refines the targets for biochemical testing while uncovering potential polypharmacological factors that might contribute to adverse events. Following initial trials, including animal models and Phase I trials, pharmacogenomics comes into play, identifying variants that could impact dosing and efficacy. This information guides the design of larger Phase III clinical trials, enabling exclusion of non-responders and tailoring drug interventions toward individuals more likely to respond positively. This comprehensive approach demonstrates the integral role of pharmacogenomics in optimizing the drug discovery process.[17]
Development of semantic model of pharmacogenomics information :
The development of a semantic model for pharmacogenetic content within Structured Product Labels (SPLs) involved using real use cases and representative pharmacogenomics statements from product labels. The focus was specifically on the pharmacogenomic content present in SPLs. Relevant sentences from these sources were analyzed to identify entities and relationships, and the Cmap concept mapping tool was employed for modeling. This informal modeling approach was chosen for its agility, facilitating rapid model development. The intention is to transition towards a more formal model through iterative refinement, incorporating input from perspectives pertinent to both pharmacological and translational considerations. This iterative process aims to enhance the model's accuracy and comprehensiveness over time.[18
Modification:
Semantic groups play a crucial role in organizing the detailed UMLS semantic types into broader categories relevant to the clinical domain. In Enhanced SemRep, five distinct semantic groups—Substance, Anatomy, Living Being, Process, and Pathology—have been defined. These groups facilitate a systematic and comprehensive approach to handling arguments in predications pertinent to pharmacogenomics. By categorizing semantic types into these groups, the model ensures a structured and well-defined framework for specifying allowable arguments in the ontological semantic predications associated with each domain. This approach enhances clarity and coherence in handling information related to pharmacogenomics within the semantic network.
The 'Substance' semantic group encompasses various categories related to chemical and biological entities. These include:
This grouping facilitates a systematic organization of diverse substances, providing a comprehensive framework for handling information related to these entities within the context of pharmacogenomics.
The 'Anatomy' semantic group comprises:
The 'Living Being' semantic group encompasses:
The 'Process' semantic group comprises:
The 'Pathology' semantic group encompasses:
The integration and maturation of the diverse components outlined above contribute to the establishment of a robust system for developing decision support systems in personalized pharmacotherapy (see Figure 1). Historically, clinical decision support systems faced challenges, including poor adoption and limited impact on clinical practice. Various factors contributed to these issues, such as: The historical challenges faced by clinical decision support systems include: A deficiency in publicly accessible formally represented biomedical and clinical knowledge connecting clinical findings with treatment recommendations. A dearth of standardized methods for representing clinical data and findings, including information about allergies, drug intolerance, phenotypic features, occurrences of diseases in close family members, or radiological findings. Addressing these challenges is crucial for the successful adoption and impact of clinical decision support systems in personalized pharmacotherapy. The integration of matured components, as described earlier, contributes to overcoming these historical limitations.
Figure 5: the components of an IT infrastructure for personalized pharmacotherapy
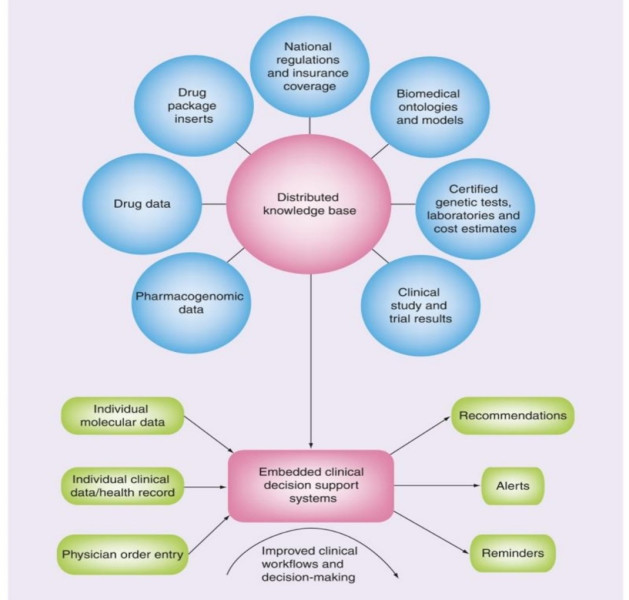
Relevant Datasets:
Datasets containing information such as genotype–phenotype associations or details about specific drugs are made publicly accessible on the World Wide Web. These datasets are formatted using Semantic Web standards.
Semantic Interlinking:
The datasets are interconnected, forming a distributed yet cohesive knowledge base. Semantic interlinking ensures meaningful connections between different pieces of information, allowing for a comprehensive understanding of pharmacogenomic relationships. Knowledge Base: The interlinked datasets collectively serve as a knowledge base. This knowledge base becomes a valuable resource for creating clinical decision support systems. Clinical Decision Support Systems: Built upon the knowledge base, clinical decision support systems are developed. These systems have the capability to analyze individual patient data, enabling healthcare professionals to make informed decisions when prescribing drugs. The integration of semantic web technologies enhances the ability of these systems to reason and provide personalized recommendations based on the available pharmacogenomic knowledge.[19]
REFERENCES


Amol V. Supekar, Tagare Chetan B., Girhe Akshay R., Tanpure Siddharth S., Zirpe Pandhori, A Review on: Pharmacogenomics with AI (Clinical Sematic Network ), Int. J. of Pharm. Sci., 2024, Vol 2, Issue 3, 230-244. https://doi.org/10.5281/zenodo.10800554
 10.5281/zenodo.10800554
10.5281/zenodo.10800554
